
The Perfect Media Series has a new home at perfectmediaserver.com. This series remains public here for informational purposes only - for questions or support please visit the new site.
Choosing how to store your data is one of the most hotly debated topics amongst data hoarders. I frequently find myself discussing this topic with friends, family, redditors and anyone else who’ll listen. Over the last 5 years I’ve tried numerous different storage methods and learned a lot along the way. Using nothing but free and open source software I’ve assembled what I believe to be the best solution of it’s type using Linux (Debian in my case), Docker, SnapRAID and MergerFS.
You’ll find out more about each of these projects in this article. I’ll also cover the setup process for each component and along the way extol the virtues of Ansible for managing all of this configuration in a sane, reproducible manner stored entirely in the source code management tool, git.
Requirements
Before we get into the meat of this (epic) article I wanted to state the requirements that this solution will fulfil. The setup must:
- act as a NAS type device serving files across the network
- support hard drives of differing / mismatched sizes
- support incremental upgrading of hard drives in batches as small as one
- group multiple hard drives under a single mount point for reads and writes
- have the capability to run multiple VMs if required via KVM
- saturate a gigabit LAN connection (be performant)
- present each drive with a separately readable filesystem
- provide fault tolerance to protect against (inevitable) hard drive failure
- checksum files to guard against bitrot
- run multiple applications at once sandboxed
- only spin up the drive(s) in use
Arguably, ‘be easy to use’ should be on this list but that’s a bit subjective isn’t it? The rest of this article will detail how to create the perfect media server, setup each component and explain how each of the core requirements above is met. There are many, many ways to skin this particular cat – I’ve probably tried most of them and each has it’s issues.
This solution is flawless.
It requires a bit of elbow grease to setup compared with other solutions but you are in complete control of every aspect of your system. The code used is all open source. There are no license fees to pay. Best of all, there’s a comprehensive guide on how you can set this up yourself too 😀 !
Introducing the tools
Let’s begin by introducing each tool mentioned above and the role it will play in our system.
EDIT: A TL;DR…
- MergerFS – a transparent layer that sits on top of the data drives providing a single mount point for reads / writes
- SnapRAID – a snapshot parity calculation tool which acts at the block level independent of filesystem providing fault tolerance in the event of a drive failure
MergerFS
- Role: Drive pooling
- Requirement(s) met: - support hard drives of differing / mistmatched sizes
- support incremental upgrading of hard drives in batches as small as one
- group multiple hard drives under a single mount point for reads and writes
- present each drive with a separately readable filesystem
- saturate a gigabit LAN connection (be performant)
- only spin up the drive(s) in use
It’s fair to say that I’ve been looking for a solution similar to MergerFS for a long time and when I read a post over on the excellent blog by zackreed.me about it I was extremely excited to check it out. I’ve tried MHDDFS, AUFS, BTRFS, unRAID, RAID (mdadm) and ZFS but they each have their faults and MergerFS “just works” TM.
As you can see, it meets a fair number of the requirements on it’s own and forms a core piece of the jigsaw but just what is MergerFS? It’s github page says:
mergerfs is a union filesystem geared towards simplifing storage and management of files across numerous commodity storage devices. It is similar to mhddfs, unionfs, and aufs.
MergerFS is JBOD (Just a Bunch Of Drives) made to appear like an ‘array’ of drives. MergerFS transparently translates read / write commands to the underlying drives from a single mount point, in my examples that is /mnt/storage. I point all my applications at /mnt/storage and forget about it, MergerFS handles the rest transparently. See the diagram below.
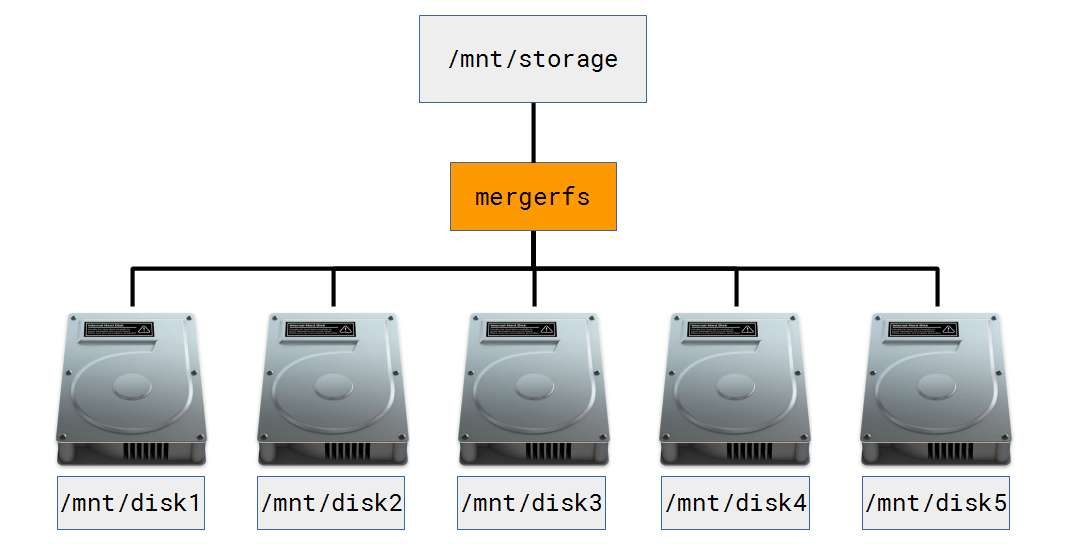
I have 5 separate data drives, they all happen to be 3TB but could be of any size (mismatched drives are supported). Each drive is formatted with it’s own filesystem, XFS in my case. Only the drive upon which data is stored will spin up when accessed and not the whole array because the filesystem on each disk is individually readable. In the event I need to pull a drive and read it’s contents out of context of the ‘array’ on another Linux system, I can. The rest of my data remains accessible too during this period, not true for RAID or ZFS. This would come in handy if I exceeded the fault tolerance level of my ‘array’, for example. In this scenario I’d only loose the data on the extra failed drives. Compare this with traditional RAID or ZFS where each drive has data striped across it meaning if you were to try and read that drive out of context, you’d be out luck. Bye, bye data.
For the home user the incremental addition of hard drives is a very important consideration. I often hear when talking about expanding a ZFS pool “just chuck in 4 more drives at once, then you can expand when you fill up your pool”. FOUR drives at once? That’s fine for the enterprise but at home, that’s likely to cost £600 in one go. No chance. Not to mention the increased simultaneous failure risk of buying 4 drives from the same batch (when drives go bad they usually fail at a similar point if from the same batch)! With MergerFS the drive addition process is as simple as partitioning the drive, adding it to the mount command in /etc/fstab and you’re done. For the record, I think ZFS is fantastic when managing enormous data sets (100+TB) – it is unrivalled. For the average home user though it’s complex, expensive and not flexible enough.
EDIT: Thanks to Skallox on reddit for bringing this article on the ‘hidden cost of ZFS‘ to my attention. It backs up my point of view quite nicely!
In addition to all the requirements that MergerFS fulfills it also has some nifty policy modes which use the available space in a smart manner. As an example let’s say we wanted to write a movie file to /mnt/storage/movies. Underneath the pooled mount point /mnt/storage we find /mnt/disk3/movies exists but /mnt/disk4 has the most free space. In this scenario it would be reasonable to expect the file to be written to disk4 wouldn’t it? Well, using the default epmfs option that wouldn’t occur. Here’s the excerpt from the manual (did I mention MergerFS has awesome documentation?!).
epmfs(existing path, most free space) – If the path exists on multiple drives use the one with the most free space and is greater than minfreespace. If no drive has at least minfreespace then fallback tomfs.
trapexit, the developer of MergerFS is extremely responsive and worked directly with me to resolve some performance issues I had. As a result I’m comfortably able to saturate a gigabit transfer over samba. MergerFS really is fantastic and is at the heart of the system. I’m so glad it exists, at last! Thanks trapexit.
SnapRAID
- Role: Provide fault tolerance / parity based protection
- Requirement(s) met: - provide fault tolerance to protect against (inevitable) hard drive failure
- checksum files to guard against bitrot
- support hard drives of differing / mistmatched sizes
SnapRAID is an application which computes parity across a set of hard drives (usually in JBOD configuration) allowing recovery from drive failure. It is known as a ‘snapshot’ RAID implementation as it is not ‘real-time’ such as mdadm, ZFS or unRAID. SnapRAID is free and open source under a GPL v3 license. It supports mismatched disk sizes although the largest must be your parity drive, more on that later. Uniquely, it runs across a plethora of OS’s such as Linux, OS X, Windows, BSD, Solaris and OpenIndiana – pretty impressive.
Supporting up to SIX parity drives SnapRAID provides potentially a very high fault tolerance and better than ZFS or BTRFS RAID implementations can manage. Data integrity is checked for bitrot using 128bit checksumming, similar to ZFS (although this uses 256bit) and allows for the silent fixing of these errors. Furthermore, any files changed since the last sync can be restored on a file by file basis allowing for quite a sophisticated backup solution at the file level. (Remember that RAID is not backup). It will also work on already populated data drives, a big win over traditional RAID. Again, it allows only the drives in use to be spun up unlike RAID which requires all drives spinning to access a file on one drive.
SnapRAID is designed to shine with large collections of files that change infrequently. A common use case is a media or home file server. Let’s say you have a 2TB collection of movies and a 2TB of TV shows, how often does that content change? Not very, is probably the answer. Does it therefore make sense to require real-time parity calculation or just run that computation once daily at a quiet time? My thoughts are that once a day for these types of files is absolutely fine. Here’s an example to help you wrap your noodle around this. You download a file and save it to disk called ‘WorstMovieEver.mkv’. This file sits on disk and is immediately available as usual but until you run the parity calculation (or parity snapshot) the file is unprotected. This means if in between your download and a parity sync and you were to experience a drive failure, that file would be unrecoverable. It should be noted that it is very simple to run a manual parity sync if the files are important using snapraid sync.
Please review your use case before using SnapRAID. It is incredibly badly suited to high turnover applications such as databases or other similar applications. If this is your use case, look at a real-time parity based solution. If you can cope with this ‘risk window’ and have a largely static file collection, SnapRAID is for you.
Docker
![]()
- Role: Run applications
- Requirement(s) met: - Run multiple applications at once
If you haven’t heard of Docker by now, where have you been? But seriously, it’s taken the application distribution world by storm. Docker containers provide a wrapper around an application making deployment extremely simple. This won’t be a full Docker tutorial (there are enough of those elsewhere) but should explain the basic concepts you’ll need to understand in order to start using it.
A standard container bundles all the libraries required by an application to run, you no longer need to know which version of Java, Apache or whatever – the person who built the container for you took care of that. Containers don’t usually ship with configuration files baked in though. This is because the contents of a container are ‘stateless’ or ‘immutable’. In English, this means the state or filesystem of the container itself cannot be modified after it is created. Wait, how do I configure my application that cannot be changed? You ‘bind mount’ a ‘volume’ into the container.
Bind mounting is an important concept to understand. By design containers are isolated to their own ‘namespace’, they have no concept of the world around them unless you explicitly allow it. For example a simple web server like nginx listens on port 80. In order for you to be able to access that web server you must tell Docker to allow it using a ‘flag’ such as -v for volume or -p for port. Full docs are available from Docker and with each LinuxServer.io Docker container too.
Here’s an example using nginx:
docker create --name nginx -p 80:80 -v /opt/appdata/nginx:/config/www linuxserver/nginx- The
-vflag allows the container access to/opt/appdata/nginxon the host - The
-pflag makes the web server available onserverip:80
By time you translate this across multiple applications (each shipping with their own dependency lists) it becomes clear why Docker containers are so popular. They allow the end user to run a plethora of applications without requiring intricate knowledge of that app. I’ll provide some examples of more media focused application docker run commands later in this article.
Installation and Configuration
With the rather lengthy explanation of each tool out the way, let’s put this thing together.
Install Debian
![]()
I value my life. I will therefore not dictate that you use Debian. I will however say that I have found it makes a great server OS for me. Use whichever distro you like, just note that my scripts and commands are aimed at apt package managers.
Learn Ansible
![]()
Once the OS is installed, it’s time set up everything else. To do this, I just run the following command.
ansible-playbook epsilon.yml -i hosts -KThis single commands executes a ‘playbook’. A playbook contains a series of ‘tasks’ grouped together under ‘roles’. This promotes reuse across multiple system. If you’d like to install docker on multiple systems, just include the docker role and so on.
Here’s a YouTube video explaining this process in a lot more detail…
epsilon.yml
- hosts: epsilon
sudo: true
roles:
- docker
- mergerfs
- snapraid
- epsilonAs you can see from the example above I have created several roles for my server called ‘epsilon’. These roles install (in order) Docker, MergerFS, SnapRAID and finally the epsilon role. The epsilon role contains all of the specific configuration that makes my server mine. This includes setting up things like samba, nfs, drive mounts, backups and more. It’s important to note that the configuration of applications is separated from the installation. For example MergerFS is installed in the mergerfs role but not configured for my system until the epsilon role is executed.
Here’s an excerpt from the epsilon role which sets up mounting the drives in my system.
- name: create /mnt points
file:
dest: \"/mnt/{{ item }}\"
state: directory
owner: nobody
group: nogroup
mode: 0777
with_items: \"{{ mntpoints }}\"
- name: mount disks
mount:
name: \"{{ item.name }}\"
src: \"{{item.src}}\"
fstype: xfs
# change to 'mounted' to auto mount
state: present
with_items:
- { name: /mnt/parity1, src: /dev/disk/by-id/ata-Hitachi_HDS5C3030ALA630_MJ1311YNG4GE8A-part1}
- { name: /mnt/disk1, src: /dev/disk/by-id/ata-Hitachi_HDS5C3030ALA630_MJ1311YNG5SD3A-part1}
- { name: /mnt/disk2, src: /dev/disk/by-id/ata-WDC_WD30EFRX-68AX9N0_WD-WCC1T0632015-part1}
- { name: /mnt/disk3, src: /dev/disk/by-id/ata-TOSHIBA_DT01ACA300_X3544DGKS-part1}
- { name: /mnt/disk4, src: /dev/disk/by-id/ata-WDC_WD30EFRX-68AX9N0_WD-WMC1T0074096-part1}
- { name: /mnt/disk5, src: /dev/disk/by-id/ata-Hitachi_HDS5C3030ALA630_MJ1311YNG7SAZA-part1}
- name: mount mergerfs array
mount:
name: /mnt/storage
src: /mnt/disk*
opts: direct_io,defaults,allow_other,minfreespace=50G,fsname=mergerfs
fstype: fuse.mergerfs
# change to 'mounted' to auto mount
state: presentThe full code can be found at github.com/IronicBadger/ansible. There is also extensive documentation available from the Ansible project at docs.ansible.com.
It’s worth familiarising yourself with concept of modules, as this is how Ansible interacts with your system. Above I showed the file and mount modules iterating over several items programatically. It takes a bit of time to get things setup just right but the time saved in the long run is totally worth it.
Media Applications
What’s the use of a media server without apps to playback all that content you’ve ‘backed up’? This is where Docker really comes into it’s own. Here’s a list of the Docker containers I run on my system docker.list
Here’s the command I used to create Plex from our very own LinuxServer.io Plex Docker container.
docker create –name plex \\ –net host \\ -e VERSION=”plexpass” \\ -e PUID=1050 -e PGID=1050 \\ -v /opt/appdata/plex:/config \\ -v /mnt/storage/:/data \\ linuxserver/plexI’m working on a tool that will automatically parse the contents of the docker.list file so that I call it in the following way newtool --create plex. That’s very much a work in progress though. There are tools like Docker compose which provide much the same functionality but I don’t like the way compose appends compose to name of each container.
I store all of my Docker appdata in /opt/appdata/<appname>. Remember the ‘bind mount’ definition I gave earlier in this article with the -v flags? This is a bind mount in action.
I back this directory up using rsnapshot meaning that in the event of a system failure I restore the appdata directory and pick up exactly where I left off! Same if I delete and recreate the containers.
LinuxServer.io is an extremely active community Docker container maintainer group. Please join us on freenode at #linuxserver.io if you have any questions about this section of the article.
Manual Installation
I’m not going to cover this in too much detail as you should be able to reverse engineer the configuration files in my Ansible repository.
Gotchas
Here’s a couple of things to watch out for…
MergerFS
I mentioned previously that the developer of MergerFS worked with me on improving it’s performance. The outcome of the discussion was to add direct_io to the line in /etc/fstab. Utilising the minfreespace option prevents drives from completely filling up and fsname means that the output of df -h is more readable.
/mnt/disk* /mnt/storage fuse.mergerfs direct_io,defaults,allow_other,minfreespace=50G,fsname=mergerfs 0 0SnapRAID
There aren’t any real gotchas here but it’s important to automate the parity syncs. I do this using the chronial snapraid-runner script.
Conclusion
This article has taken many hours to write and research so if you found it useful, please leave a comment below and let me know. It is my intention to do some screencasts on Ansible to make it more palatable to this audience.
There are many options open to you if you’re looking to store large collections of media these days. This is a good thing. It is also a bad thing. Too much choice can be bewildering. That is why I have taken the time to explain the reasons why I use each component. That’s not to say this is the perfect solution for everyone however, it is for me.
I really hope you enjoyed reading this and will get in touch on IRC on freenode #linuxserver.io where I’m @IronicBadger. I’m also on Twitter. Please send in your questions to the new LinuxServer podcast. Thanks for reading.