
Any audiophile will attest to compiling albums well into the hundreds, or even thousands. When a music collection grows, it can become harder to keep it well managed.
The main problem with managing a music collection is, generally, each collector has their own way of archiving their music. We all have our own preferences over track names, album art, and meta data. Providers of music such as Google Play, iTunes, and self-signed artists won't necessarily agree on those preferences, so it's up to you to sort it out yourself. That process is incredibly time consuming, especially if you're about to import a pre-existing collection.
beets: A powerful import and management tool
beets is an incredible tool; one which any serious music collector should consider using. It scans though your original collection and will automatically scrape data from a predefined online source such as MusicBrainz to correct any subtle inconsistencies that may have found their way into a track's metadata. This includes typos, or international misspellings. Think of it as a data cleanse tool that you pass your music into, getting a clean and properly tagged set of files out the other end.
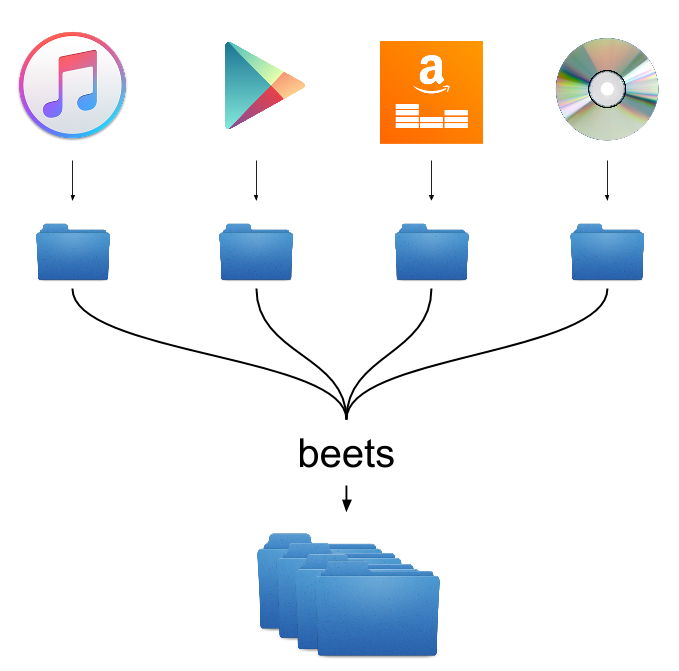
Why use a tool like this?
Generally speaking, we obtain our music in many different ways; be it buying from a high street store, or downloading from one of the many online retailers. After years and even decades of collecting music, your albums will likely have come from different places. Each retailer/content supplier is going to store and format their music in different ways. It's great for them but not so great for your music collection. This is where beets excels. It takes your entire library - which likely consists of music from iTunes, Google Play Music, Amazon, and even CD backups from the older side of your collection - and consolidates all of the metadata into a single format. It gives you control over how you want your music to be archived and read. It makes it consistent.
Getting beets
beets is written in Python, so has a dependency on the Python libraries in order for it to work. However, we have written a handy docker image for beets, which saves you the trouble of ensuring you have all of the correct dependencies installed. If you don't have Docker installed, or prefer not to use it, you can find out how to install it manually on the beets website.
Grab the beets image
Firstly, we'll need to get beets installed. Below is a docker command that pulls down the latest alpine build of our beets image and maps all of the necessary folders to it. Before running this command, review the volume mappings and make sure you map them correctly.
{CONFIG_DIR}is the configuration directory. This holds all of the beets-specific configuration files, including the music database. We tend to put our docker configuration directories under our/home/{user}directory (e.g./home/josh/beets).{MUSIC_DIR}is where you wish your cleansed music to reside once imported. In my case, I have my music collection in/storage/media/music.{DUMP_DIR}is the folder where the unclean data currently lives. If you already have a music collection, this can point there.-
{GID}and{UID}are the group and user ids that the running container will map to. By default, docker containers run as root, which isn't always preferable. Setting these environment parameters will ensure anything this container does will be under the correct user. Most Linux users will prefer to use their own account, which often maps to UID=1000 GID=1000.docker create \ --name=beets \ -v /etc/localtime:/etc/localtime:ro \ -v {CONFIG_DIR}:/config \ -v {MUSIC_DIR}:/music \ -v {DUMP_DIR}:/downloads \ -e PGID={GID} -e PUID={UID} \ -p 8337:8337 \ linuxserver/beets
Once downloaded and created, the beets container can be started:
docker start beetsConfiguring beets
With great power comes great configuration. The level of configuration in beets is nothing short of incredible. If you have some time set aside, I recommend having a peruse of the available options so you have a better and more grounded idea of what exactly beets is capable of (which is a lot).
The nitty gritty
All of the settings are stored in a file called config.yaml, residing in the /config folder in the docker container (remember we mapped this to the host?). By volumising this folder, we can access the configuration file and change it depending on our own preferences.
By default, our docker image uses a very basic set up of the configuration - an example of which you'll find in config.yaml below:
plugins: fetchart embedart convert scrub replaygain lastgenre chroma web
directory: /music
library: /config/musiclibrary.blb
art_filename: albumart
threaded: yes
original_date: no
per_disc_numbering: no
convert:
auto: no
ffmpeg: /usr/bin/ffmpeg
opts: -ab 320k -ac 2 -ar 48000
max_bitrate: 320
threads: 1
paths:
default: $albumartist/$album%aunique{}/$track - $title
singleton: Non-Album/$artist - $title
comp: Compilations/$album%aunique{}/$track - $title
albumtype_soundtrack: Soundtracks/$album/$track $title
import:
write: yes
copy: no
move: yes
resume: ask
incremental: yes
quiet_fallback: skip
timid: no
log: /config/beet.logThe default configuration in our docker image will:
- Scan the folder defined in the execution of beets for music and scrape the metadata from MusicBrainz.
- If it finds any discrepancies (misspelled track names, for example), it will correct them based on a similarity value. The files will be renamed according to a standard pattern for each track and album (
default: $albumartist/$album%aunique{}/$track - $title). - The cleansed music will be moved (
move: yes) into the designated music folder (directory: /music). - If one does not already exist, beets will also download a relevant albumart.jpg file for each album being imported.
Changing the configuration
The section you are most likely going to be tweaking is the paths node. This details how the files themselves will be laid out and named. In the case of our default config, the folder structure will look like this:
music/
An Artist/
Their First Album/
01 - A Track.mp3
02 - Another Track.mp3
Compilations/
Non-Album/
A Great Band - Their Only Song.mp3
Soundtracks/
That Movie You Saw That One Time OST/
01 Opening Scene.mp3
02 Closing Credits.mp3Running an import
Your music collection is ready; you have beets warmed up; now it's time to run the import! If you installed beets via our docker image, the executable will only be visible inside the running container. Normally you'll need to run another docker command to open an interactive shell inside the container then run the beets executable. That extra step, while not particularly time-consuming, can be a bit annoying, so here is an all-in-one command that you can use instead:
docker exec -u abc -it beets /bin/bash -c 'beet import /downloads'If your collection spans hundreds/thousands of albums, prepare to set aside a couple of hours
While importing, beets will scan each album individually, scrape the relevant information online and then match up the new data against each track. Most of the time, assuming your collection isn't completely ruined by typos or irregular album placement, this process will be fine on its own. However, if your collection spans hundreds or even thousands of albums, prepare to set aside at least a couple of hours while this import runs.
When beets is unable to find information on a particular album from its online source, it will ask you what to do. This is as per our configuration above (resume: ask), and will occur when beets can't find a match within the similarity threshold, which by default is set to 96% likelihood of a match.
If this happens, you'll need to manually intervene and tell it what you want to do. It will provide you with a set of options (e.g. best matched track/album name) and will wait until you tell it what to do. You can also skip the import for that particular track and come back to it at the end. The same occurs if beets finds a duplicate album or track in your collection.
An example of an import
The configuration I have in beets says that track files from an album should be named as $track - $title, meaning the import will cleanse the data by adding a hyphen between the track number and its name.
When running the import, the first thing to notice is beets will attempt a correction of track names. It turns out it didn't agree with iTunes' choice of album name or lack of punctuation on one of the tracks, so it told me:
Correcting tags from:
Henry Jackman - X-Men - First Class (Original Motion Picture Soundtrack)
To:
Henry Jackman - X-Men: First Class: Original Motion Picture Soundtrack
URL:
http://musicbrainz.org/release/3d6778bb-8189-4a6b-bd17-fcff45c1302b
(Similarity: 100.0%) (CD, 2011, US, Sony Classical)
* What Am I thinking -> What Am I Thinking?
* Coup d'état -> Coup d'ÉtatIt has also done some folder/file name replacement as well. As per the config.yaml, beets will replace any characters likely to upset various operating system naming standards (looking at you, Windows). The album directory has had its colons stripped and replaced by underscores. Now if I looks in the output folder after the import, I can see that the album tracks have been renamed properly, and an albumart.jpg has been added.
Example of a low similarity match
If the similarity is too low, beets will ask you what to do.
Correcting tags from:
30 Seconds To Mars - 30 Seconds To Mars
To:
Thirty Seconds to Mars - 30 Seconds to Mars
URL:
http://musicbrainz.org/release/c3b239c6-60fd-4798-99d8-a0373147d779
(Similarity: 90.4%) (tracks, artist, unmatched tracks) (CD, 2002, US, Immortal Records)
* Capricorn -> Capricorn (A Brand New Name) (title)
* Edge Of The Earth (4:45) -> Edge of the Earth (3:57) (id, length)
* Buddha For Mary -> Buddha for Mary
* Welcome To The Universe -> Welcome to the Universe
* The End Of The Beginning -> End of the Beginning (title)
Unmatched tracks (1):
! Capricorn (Acoustic) (#13) (3:28)
[A]pply, More candidates, Skip, Use as-is, as Tracks, Group albums,The [A] signifies that it is the default option (so you can hit RETURN to keep going) but it is also defaulted to a timer, meaning if you wait long enough, it'll accept its decision automatically. Quite handy.
What next
This is an incredibly basic guide regarding the set up, configuration and running of beets. Because its capability is so far reaching, I simply couldn't note all of it down. Now it's up to you to decide how you want beets to behave with your music collection. Don't forget to check out the plugins page to see if there are any extras that might fit your needs!
I have personally added one plugin, called ftintitle, which makes sure that when beets is renaming files, it does not split albums that contain 'featured' artists. By default, beets will put the 'feat. Artist' as part of the $artist, rather than appending it to the $title. This is a great example of how beets can be configured to your own tastes (in this case, my tastes).
Just add the name of the plugin to the plugins: section at the top of config.yaml.
Updating your clean data
If it has been a while since your last import, the metadata may have changed on MusicBrainz. You can run an update to make sure your data stays current:
docker exec -it beets /bin/bash -c 'beet update'If you make any configuration changes that would alter the physical file structure of your collection, you will need to run a fresh import on the clean music folder:
docker exec -it beets /bin/bash -c 'beet import /music'